Joker uses one reference image to generate a 3D reconstruction with a novel extreme expression. The target expression is defined through 3DMM parameters and text prompts. The text prompts effectively resolve ambiguities in the 3DMM input and can control emotion-related expression subtleties and tongue articulation.
Abstract
We introduce Joker, a new method for the conditional synthesis of 3D human heads with
extreme
expressions. Given a single reference image of a person, we synthesize a volumetric human
head
with the reference’s identity and a new expression. We offer control over the expression via
a
3D morphable model (3DMM) and textual inputs. This multi-modal conditioning signal is
essential
since 3DMMs alone fail to define subtle emotional changes and extreme expressions, including
those involving the mouth cavity and tongue articulation. Our method is built upon a 2D
diffusion-based prior that generalizes well to out-of-domain samples, such as sculptures,
heavy
makeup, and paintings while achieving high levels of expressiveness. To improve view
consistency, we propose a new 3D distillation technique that converts predictions of our 2D
prior into a neural radiance field (NeRF). Both the 2D prior and our distillation technique
produce state-of-the-art results, which are confirmed by our extensive evaluations. Also, to
the
best of our knowledge, our method is the first to achieve view-consistent extreme tongue
articulation.
Method
Overview: Our Method consists of 2 components: a 2D Diffusion-Based Prior and a
Progressive
3D Distillation
procedure.
The 2D prior predicts images of the reference identity while expression and pose are controlled
through a 3DMM and text prompts.
During the Progressive 3D Distillation, predictions of the 2D prior are used to generate a 3D
reconstruction.

2D Diffusion-Based Prior: Our 2D Diffusion-Based Prior consists of 3 components all of which are constructed as UNets which are initialized from pretrained StableDiffusion 1.5 weights. The Denoising Network takes latent noise and a driving prompt as input and generates the output images in a standard latent-diffusion denoising process. The Reference Network takes the reference image as input, and passes it through its UNet structure. The keys and values of the self-attention layers are appended to their respective counterparts in the Denoising Network (see DiffPortrait3D for more details). The Driving Network is constructed as a ControlNet to drive the Denoising Network with normal map renderings of the 3DMM.
Progressive 3D Distillation: During our Progressive 3D Distillation, predictions of the 2D Prior are used to optimize a 3D reconstruction (NeRF). It is performed in two stages that differ in how the target images are generated and how frequently they are updated.
Stage1: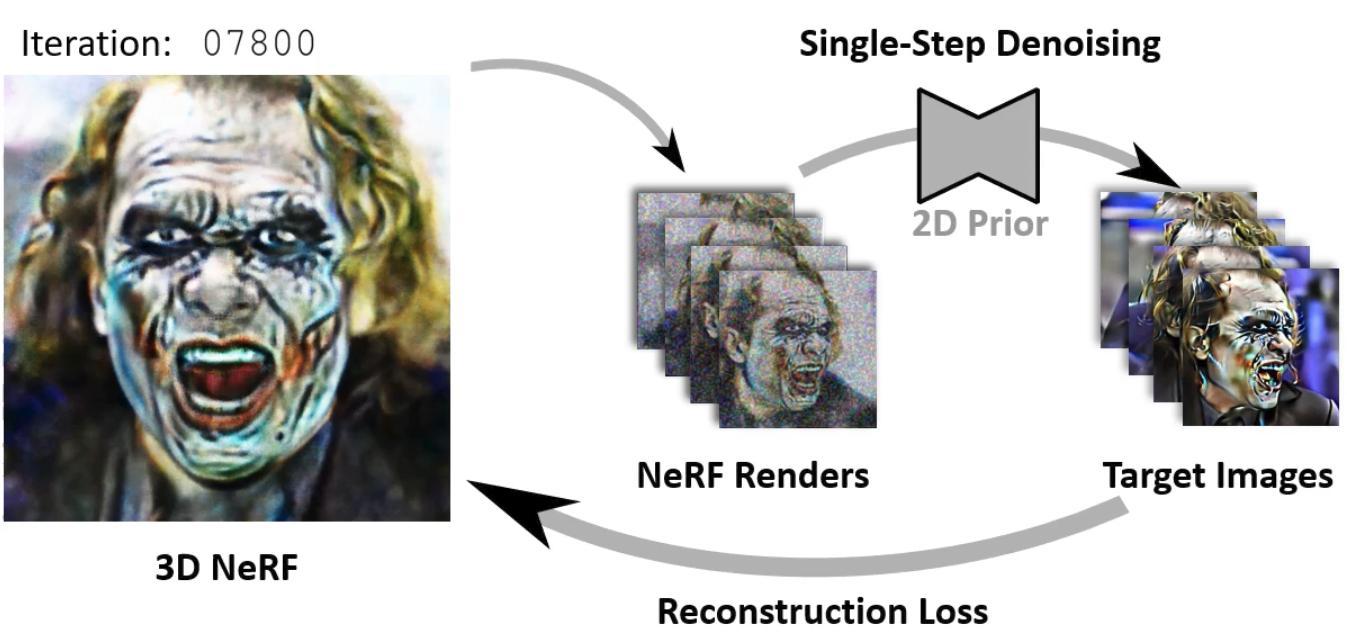 In Stage 1, the NeRF is rendered under several views.
The renderings are noised
according to discrete noise levels from a DDIM noise schedule and denoised in a single inference
step using the 2D prior. The resulting images are used as targets to optimize the NeRF for
several
iterations. This procedure is repeated several times while the amplitude of the applied noise
decreases monotonically.
Stage 1 is interrupted after ~60% of the noise levels and followed by Stage 2.
In Stage 1, the NeRF is rendered under several views.
The renderings are noised
according to discrete noise levels from a DDIM noise schedule and denoised in a single inference
step using the 2D prior. The resulting images are used as targets to optimize the NeRF for
several
iterations. This procedure is repeated several times while the amplitude of the applied noise
decreases monotonically.
Stage 1 is interrupted after ~60% of the noise levels and followed by Stage 2.
Stage2: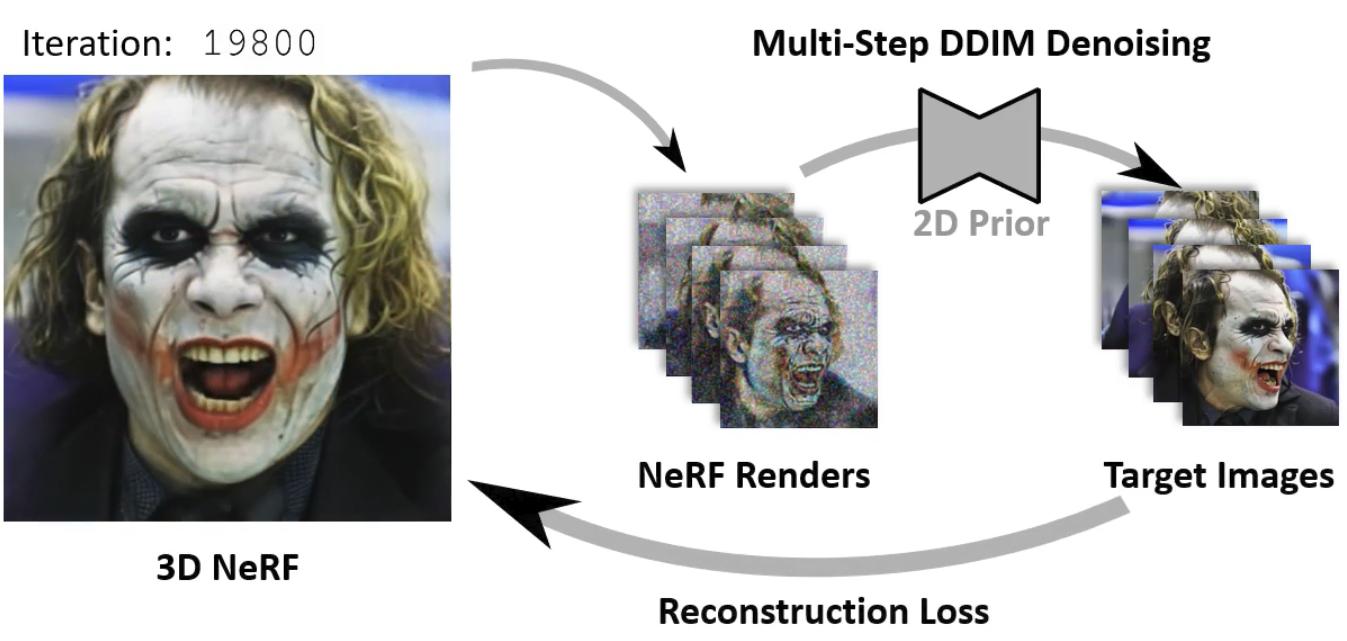 In Stage 2, we initalize the NeRF from the distillation
result of Stage 1. Again
the
NeRF is rendered under several views and the renderings are noised. This time, the target images
are
predicted in a multi-step DDIM denoising process over the remaining noise levels of the
predefined
noise schedule. The NeRF is optimized against the resulting images until convergence. We found
that
this 2-staged approach improves view-consistency and synthesis quality of the 3D reconstruction.
In Stage 2, we initalize the NeRF from the distillation
result of Stage 1. Again
the
NeRF is rendered under several views and the renderings are noised. This time, the target images
are
predicted in a multi-step DDIM denoising process over the remaining noise levels of the
predefined
noise schedule. The NeRF is optimized against the resulting images until convergence. We found
that
this 2-staged approach improves view-consistency and synthesis quality of the 3D reconstruction.
2D Diffusion-Based Prior: Our 2D Diffusion-Based Prior consists of 3 components all of which are constructed as UNets which are initialized from pretrained StableDiffusion 1.5 weights. The Denoising Network takes latent noise and a driving prompt as input and generates the output images in a standard latent-diffusion denoising process. The Reference Network takes the reference image as input, and passes it through its UNet structure. The keys and values of the self-attention layers are appended to their respective counterparts in the Denoising Network (see DiffPortrait3D for more details). The Driving Network is constructed as a ControlNet to drive the Denoising Network with normal map renderings of the 3DMM.
Progressive 3D Distillation: During our Progressive 3D Distillation, predictions of the 2D Prior are used to optimize a 3D reconstruction (NeRF). It is performed in two stages that differ in how the target images are generated and how frequently they are updated.
Stage1:
In Stage 1, the NeRF is rendered under several views.
The renderings are noised
according to discrete noise levels from a DDIM noise schedule and denoised in a single inference
step using the 2D prior. The resulting images are used as targets to optimize the NeRF for
several
iterations. This procedure is repeated several times while the amplitude of the applied noise
decreases monotonically.
Stage 1 is interrupted after ~60% of the noise levels and followed by Stage 2.
Stage2:
In Stage 2, we initalize the NeRF from the distillation
result of Stage 1. Again
the
NeRF is rendered under several views and the renderings are noised. This time, the target images
are
predicted in a multi-step DDIM denoising process over the remaining noise levels of the
predefined
noise schedule. The NeRF is optimized against the resulting images until convergence. We found
that
this 2-staged approach improves view-consistency and synthesis quality of the 3D reconstruction.
Baseline Comparisons



























Paper

BibTeX
@misc{prinzler2024joker,
title={Joker: Conditional 3D Head Synthesis with Extreme Facial Expressions},
author={Malte Prinzler and Egor Zakharov and Vanessa Sklyarova and Berna Kabadayi and Justus Thies},
year={2024},
eprint={2410.16395},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2410.16395},
}